Recent image tone adjustment (or enhancement) approaches have predominantly adopted supervised learning for learning human-centric perceptual assessment. However, these approaches are constrained by intrinsic challenges of supervised learning.
Primarily, the requirement for expertly-curated or retouched images escalates the data acquisition expenses. Moreover, their coverage of target style is confined to stylistic variants inferred from the training data.
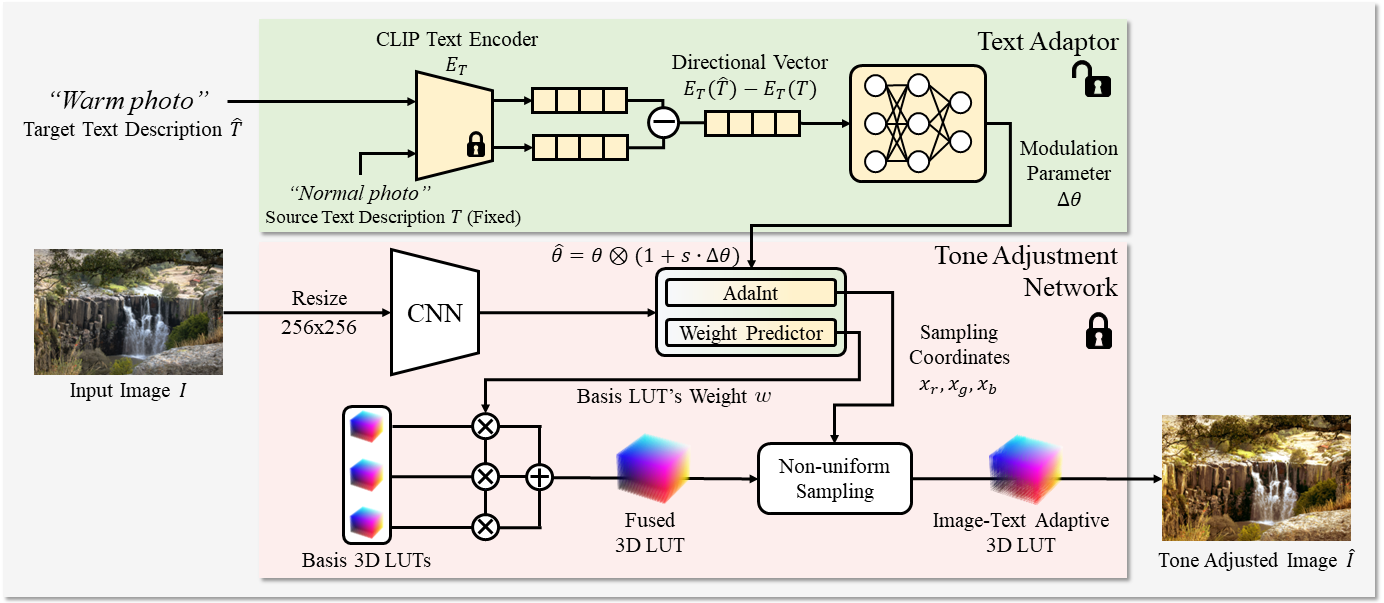
To surmount the above challenges, we propose an unsupervised learning-based approach for text-based image tone adjustment method, CLIPtone, that extends an existing image enhancement method to accommodate natural language descriptions.
Specifically, we design a hyper-network to adaptively modulate the pretrained parameters of the backbone model based on text description.
To assess whether the adjusted image aligns with the text description without ground truth image, we utilize CLIP, which is trained on a vast set of language-image pairs and thus encompasses knowledge of human perception.
The major advantages of our approach are three fold: (i) minimal data collection expenses, (ii) support for a range of adjustments, and (iii) the ability to handle novel text descriptions unseen in training.
Our approach's efficacy is demonstrated through comprehensive experiments, including a user study.